- Študentje podatkovnih ved na konferenci NeurIPS 2022
Novice
Pet skupin magistrskih študentov je v okviru izziva ML Reproducibility challenge 2021 predstavilo svoje delo na eni izmed najprestižnejših in najbolj konkurenčnih konferenc na področju strojnega učenja in računske nevroznanosti na svetu. Udeležbo sta omogočila FRI in pobuda DataScience@UL-FRI.
Študentje magistrske študijske smeri Podatkovne vede so v minulem študijskem letu, v okviru obveznosti pri predmetu Strojno učenje za podatkovne vede 2, sodelovali v mednarodnem izzivu za preverjanje ponovljivosti dosežkov vrhunskih del na področju strojnega učenja ML Reproducibility challenge 2021. Devet študentov je bilo na izzivu uspešnih, njihova dela pa so bila objavljena v reviji ReScience C, zvezek 8/2[1]. Pet skupin študentov je svoje delo med 28. novembrom in 9. decembrom letos predstavilo tudi na inavguralni predstavitvi revij (angl. Journal Showcase), na mednarodni konferenci o strojnem učenju NeurIPS 2022 v New Orleansu v ZDA.
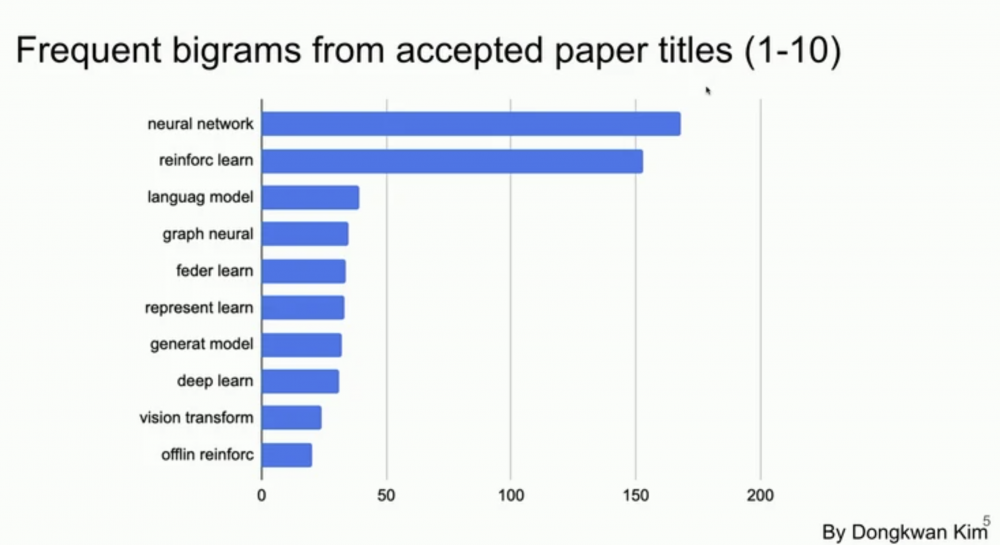
Conference on Neural Information Processing Systems (NeurIPS) velja za eno izmed najprestižnejših in najbolj konkurenčnih konferenc na področju strojnega učenja in računske nevroznanosti. Na letošnjo konferenco je bilo oddanih skoraj 10 000 člankov, sprejeta je bila manj kot tretjina. Analiza vsebine člankov glede na naslove priča o večinski razpravi o nevronskih mrežah in spodbujevalnem učenju, druge pogoste teme pa so vključevale velike jezikovne modele, grafovske nevronske mreže, generativno in federirano učenje ter rabo transformerjev v računalniškem vidu.
Udeleženi študentje FRI so svoje članke predstavili v obliki posterjev: peterica na enem izmed šestih srečanj v prvem tednu konference v New Orleansu in ena študentka na daljavo v drugem tednu konference. Ob več tisoč predstavitvah najsodobnejših idej s področja strojnega učenja, so študentje lahko prisluhnili tudi predavanjem 6 slavnostnih govorcev, med drugimi tudi predavanju prejemnika nagrade Test of Time Award za svoje delo na prebojem Imagenet-u, Geoffreyja Hintona.

Benjamin Džubur je v delu, ki ga je predstavil na konferenci, reproduciral rezultate članka »A Cluster-Based Approach for Improving Isotropy in Contextual Embedding Space«, v katerem je predlagana nova metoda za postprocesiranje množice vložitev globokih modelov NLP. Večino originalnih rezultatov je uspešno reproduciral, ne pa tudi nekaterih, ki se nanašajo na vložitve iz prednaučenega modela GPT-2 (povezava do članka).
Domen Vreš je z Matijem Terškom in Mašo Kljun poizkušal reproducirati rezultate članka »Learning to Count Everything«, v katerem je predlagana nova arhitektura za štetje objektov na slikah. Arhitektura deluje na principu učenja s par primerki (few-shot learning). V sklopu dela so uspešno reproducirali rezultate avtorjev, z izjemo trditve, da povečanje števila primerkov izboljša kakovost modela (povezava do članka).
Vid Stropnik in Maruša Oražem sta se ukvarjala z idejami dela »Graph Edit Networks«, v katerem je predlagana nova izhodna plast za grafovske nevronske mreže, za obravnavo markovskih problemov grafovskih časovnih vrst. Tudi njima je uspela reprodukcija večine trditev, ki jih v članku postavijo avtorji, posebej pa sta opozorila na pomanjkljivo ravnanje z učnimi in testnimi podatki, in eksperimente ponovila v transparentnejšem okolju. Na konferenci sta spoznala tudi avtorje izvirnega dela (povezava do članka).
Žiga Trojer je želel reproducirati rezultate dela »Transparent Object Tracking Benchmark«, v katerem so predlagali novo primerjalno zbirko za sledenje prosojnim objektom ter predlagali najsodobnejši sledilnik za njihovo rabo. Uspešno je potrdil dve od treh trditev, - dejstvo, da je predlagani sledilnik boljši od primerjanih alternativ in da vključitev prosojnih značilk pozitivno vpliva na sledenje. Zavrnil je trditev, da predlagani algoritem dobro obvlada vse izzive v predlagani primerjalni podatkovni zbirki (povezava do članka).
Urša Zrimšek je reproducirala članek »Learning Unknown from Correlations: Graph Neural Network for Inter-novel-protein Interaction Prediction«, ki rešuje problem izgube natančnosti pri napovedovanju interakcij med nepoznanimi proteini. Kritično je obravnavala predlagan način evalvacije in primerjala predlagani model s prejšnjim najboljšim. Vse trditve je vsaj deloma potrdila (povezava do članka).